Version 7.4 introduces a new database format and although the fundamental concepts remain unchanged from prior versions, there are several improvements and changes some of which substantial. It is important that you carefully read the present release notes and evaluate the impact of such changes. Some of the most significant improvements brought by version 7.4 on the database are
The management of cubes at daily level is now optimized: cubes structured by Day are now extremely more compressed that in prior versions, of a factor ranging from 10 times to 20 or 30 times more compressed. This not only strongly reduces the size of databases which have cubes at Day level but also drastically improves performance of reports using the Daily information.
DataReader with a Select: when running a DataReader from a procedure, it is possible to limit the scope of the DataReader to the active Select of the procedure. When a DataReader is limited by the Select, it will replace or append data to the cubes but only within the range of the Select. This is a major change from prior versions as it applies also to the behaviour of the Replace function.
The code and description length of entities is now dynamic. It is no longer necessary to specify the size for the entity code and for the entity descriptions. When entity members are loaded (manually or though a DataReader), the system will dynamically adjust the size.
The text cube data type is of dynamic and unlimited length. There are no longer the two data types, text32 and text224, but only a single Text data type which dynamically adjusts to the size of the incoming data. The length of the text that can be stored in a single cell of a text cube is no longer limited to 224 characters but is dynamic.
The internal compression algorithm for storing Board cubes structured by Day is now changed and provides a much higher degree of compression. Cubes structured by Day are not only smaller in size but perform significantly better in all I/O operations, therefore in DataReaders, Dataflows and in reports in general (all Layouts). There are no actions to take to adopt the new compression algorithm: cubes newly created are managed with the new compression method and if you are converting a database from version 7.3, the daily cubes are also automatically converted to the new format during the conversion process. The new algorithm provides a compression which can be 10 to 30 or more times higher than prior versions.
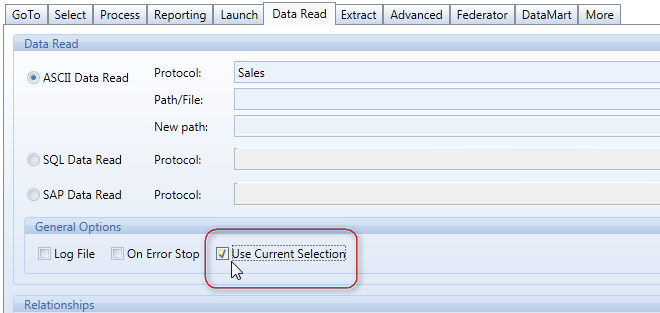
The Datareaders can now be limited by the Select when used in a procedure. This option is relevant only if a DataReader feeds one or more cubes. When configuring a Datareader, it is possible enable the option called Use Current Selection (see image below): this will limit the DataReader to the range of the select of the procedure. Note that if the DataReader uses the Replace option, then this option limits the scope of the Replace function within the limits of the Select.
Let's for example consider the cube Closing Balance dimensioned by Month, Account, Company, that needs to be populated with data from different sources (for example different databases), one for each company. It is possible to create a procedure as follows:
step 1 - Action Select on Company = "US"
step 2 - Action DataReader "Load Trial Balance of US company" which connects to the database of the US company and populates the Closing Balance cube with Replace
step 3 - Action Select
step 4 - Action Select on Company = "UK"
step 5 - Action DataReader "Load Trial Balance of UK company" which connects to the database of the UK company and populates the Closing Balance cube with Replace
step 6 - Action Select on Company = "CH"
... and so on for each company.
When step 2 if executed, the source table is read and Replace function identifies the time periods (Months) present. Then when it clears the will clear Closing Balance cube but only for the Company US . Similarly, the step 4 will only replace data for the company UK, without affecting the data of the US company loaded at step 2.
The code and description of an entity are now dynamic in length. Note that the code length and description length parameters still exist in the interface, for back-compatibility, but they no longer represent a limit to the size of the incoming data. When defining an entity, it is still required to type the code and description length however these can be dynamically changed. For example, if you create an entity with the code length of 5 characters, it is possible to load, manually or through a Datareader, a code of 6 characters or more: this item will not be discarded nor truncated (as was happening with prior version), but the length of the entity code is automatically increased by Board by multiples of 5.
IMPORTANT NOTE !!
If you are migrating a database from version 7.3 to 7.4, this changes implies that you may have to review some DataReaders, in particular SQL DataReaders, where you are loading a field of a table which is for example 10 characters, into an entity which has a smaller code width, for example of 5 characters: Board version 7.3 was automatically truncating the incoming data to 5 characters but 7.4 will not therefore if there are codes longer than 5 characters they will be added to the entity. If you need to truncate the incoming field to 5 characters, add to the SQL statement the TRUNC function or apply an ETL to truncate the incoming data.
The code and description lengths are still used in version 7.4 by the Extract action when extracting to fixed width format, however since the size of these fields is now dynamic, it is recommended to now abandon this extract format and substitute it with CSV format (tab delimited) which better fits the new dynamic nature of theses properties.
It is now possible to change the Maximum Item Number of an entity without having to clear the entity with the only restriction that the entity should not be used by any cube version containing data. For example, if you run the Clear All cubes function then it is possible to change the Max Item Nr of any entity in the database without having to clear the entities.
If you need to modify the Max Item Nr of an entity when the database is populated, it is sufficient to clear all the cube version which use that entity, in order to be able to change it. Since it is no longer required to clear the entity itself, any existing selection in procedures or in Capsules will not be affected by this operation.
When creating a new entity, it is not required to define the Max Item Nr, nor are required the code width and description width. It is possible to create an entity and leaving all the three parameters to zero. it is then possible to populate the entity with a Datareader and then define the Max Item Nr according to the actual number of members which the entity contains. If the entity is not used by any cube version, then the Max Item Nr can be left to zero (undefined). If an entity is used by a cube version, the cube cannot be populated if the Max Item Nr is zero, a non null value must be given.
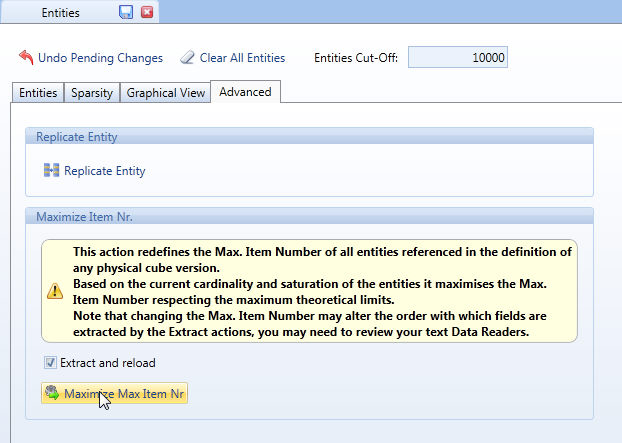
A new function, called Maximize Item Number can automatically define the Max Item Number of entities as explained hereafter.
Note
Changing the Max Item Nr of entities can change the order with which fields are extracted by the Extract cube function, therefore after such a change you may need to review your text Datareaders which read files extracted from a Board database.
This new function facilitates the definition of a Board database by automatically determining the Max item Number of entities. To use this function, the entities should be populated with a significant set of data and all the required cubes should have been created. The Max Item Nr are determined combining the following factors: the entity saturation is set equal for all entities, allowing growth in the number of members, then the cube structures are considered and the Max Item Nr are increased to the maximum value that remains within the limits of sparse and non sparse structures. The Max item Nr are maximized initially trying to maintain the sparse structures to 64-bit addressing and if not possible then to 128-bit structures.
This option automatically extracts all cube contents to text file, then automatically reloads all extracted cubes after the Max Item Nr have been changed. If this option is not enabled, the function Maximize Item Nr clears all cubes.
NOTE
The Maximize Item Nr function is a help for the database developer. It must be executed in a test or development environment, while no other Board databases are being used. The execution may take several minutes or even hours if the Extract and Reload option is used. Make a back-up of your database before executing it.
The Text data type of cubes, is now dynamic and unlimited, although it is recommended to limit the text of a single cell to a reasonable size: one to two thousand characters at most, in order to be able to display the text correctly and entirely in a single cell of a Dataview. The former cubes of type Text32 and Text224 are automatically converted to the new dynamic type Text by the automatic converter program.
Given the new dynamic nature of text cubes,
- if you use ASCII DataReaders to populate text cubes, it is recommended to change the DataReader format from fixed width to CSV format.
- if you have any procedures that extract text cubes to file, it is recommended, to change the extraction file format from fixed width to tab-delimited file (CSV format).
Note that when a text cube is extracted, the carriage-return (new line) and tabulator characters are omitted therefore if a user inputs a multi-line comment in a text cube, when the cube is extracted the text is converted to a single line text.
A new native backup function allows to make a full Backup of your database while the server is running. This backup function creates a snapshot of the database by making a safe copy of the database files into a backup directory. This native backup function should now be used for making your backups as it grants consistency of the database: if any update operation is in progress, the backup function waits for the ongoing update process to commit and then makes a copy of the database files while preventing other update operations from taking place. When this backup is executed, the database is automatically exclusively locked for updates and is automatically released at the end of the operation.
This function is powerful and important as it supports hot-backups: it run while the Board service is running, it doesn't require any down-time. it is recommended that you review your backup strategies and take advantage of the new feature offered by the Board server. The former back-up strategies, generally requiring to stop the service, copy the DTBX file and then restart the service are now still possible but less valid as the restart of the Board service may take several minutes for loading the database in memory.
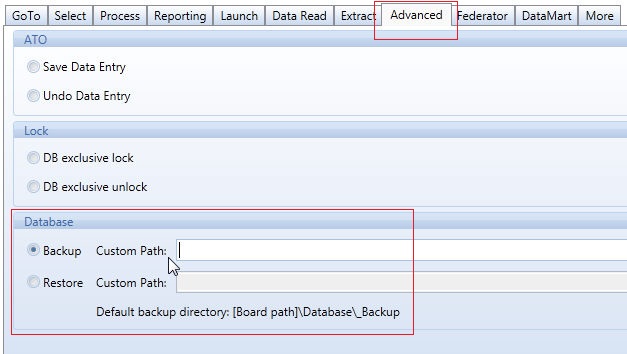
The Backup function uses a Backup directory to save a copy of the HBMP database. The directory where to save the backup can be configured on the Board Server as shown in the following image.
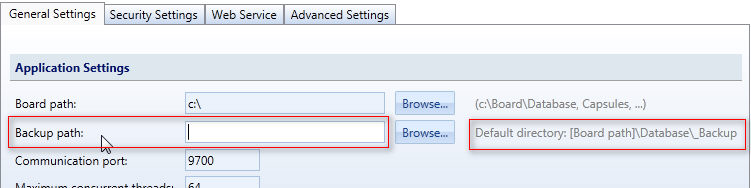
If no path is defined, a default directory is used \Board\Database\_Backup .
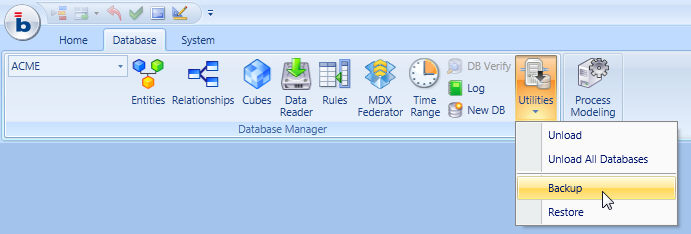
To make a backup of a database, open the database then click the Backup function found on the Utilities icon of the ribbon bar as illustrated hereafter.
The backup function can also be integrated into a Board Procedure as a Backup Action.
Note that the backup function creates a full copy of the database directory in the backup directory. it is then left to the responsibility of the system administrator to compress, historicize and move the back-up to a different repository.
To restore a database from a prior backup: open the database then click the Restore function found on the Utilities icon of the ribbon bar. This action takes the HBMP database from the default backup directory and puts it into the Board\Database directory, overwriting the current copy. This operation is done while exclusively locking the database so that other action can be taken on the database until the backup has been fully restored.
Given the improved performance of the Board server, response times of reports significantly improve in comparison to prior versions. If you are migrating an application from version 7.3, you should review the cube version since it is likely that less versions are required however it is still often necessary to create pre-aggregated versions in order to grant the best possible performance to end-user, though generally only when data volumes are high (cubes with several entities having hundreds of thousands of members). A good approach could be to initially remove all pre-aggregates, evaluate the response times and eventually create some aggregate versions.
A new optimizer function supports the database designer in the creation of cube versions. When a cube has one version only, a drop-down list to the right of the cube definition window allows to choose from three options Few/Normal/Many. Choosing one of the three options, triggers the optimizer which will automatically generate some aggregated versions. The underlying algorithm evaluates the current cardinality of the entities by which the cube is defined generates aggregates likely to provide performance improvements. The three levels, Few/Normal/Many regulate the number of versions created by the optimizer giving more or less priority to performance versus disk space or RAM utilisation: the option Many produces more versions but will consume more RAM (if in-Memory is used) and more disk space; the lowest level is Few, which creates only a few versions thus saving RAM and disk.
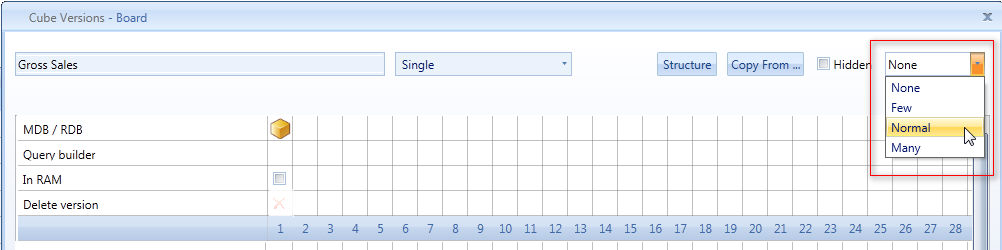
It is possible to run the optimizer also after the first version of the cube has been loaded with data, in this case the versions created by the optimizer must be populated using the Align function.
When a Board server is configured to use the Hybrid mode, by default only the database meta-data, the data-dictionary and the bitmaps are loaded in RAM when the database is opened. However it is still possible to set some cubes to be managed fully In-Memory. This can be convenient for the most commonly used cubes or for cubes that are subject to manual data-entry or to DataFlows executed by end-users of the Board application.
Tick the In-RAM check-box of a version to set it to be managed fully in-memory.
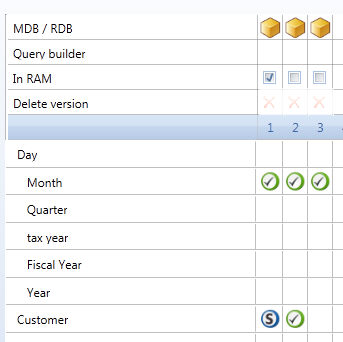
Note that the behaviour of this In-RAM option has profoundly changed from that of prior versions: the former implementation of In-RAM cubes was completely different and no longer exists in the HBMP technology.
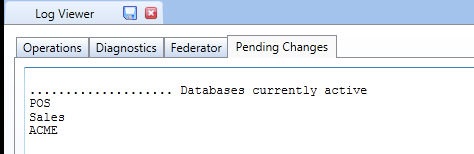
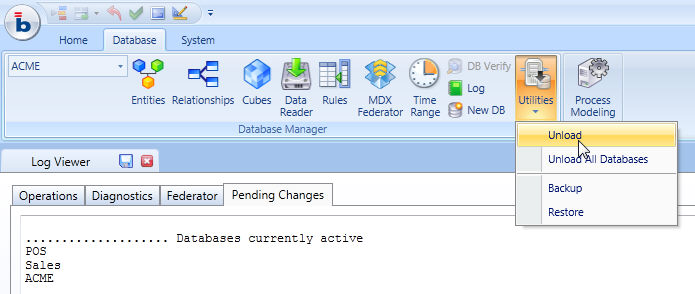
Whenever a database is accessed by a user, it is loaded in memory (even in case you use Hybrid mode, the data dictionary and other meta-data is loaded in memory). The database is then retained in memory, even after the user's request has been executed, until the Board service is stopped. It is possible to know which databases are currently opened by the Board server by going to the Log window, a new tab named Pending Changes shows the list of databases currently open as illustrated in the following picture.
To release a database from the server's memory, use the Unload database function: click the Utilities icon located in the ribbon bar then select Unload to unload the selected database or select Unload All Databases to close all active databases.
The Entity Booster, setting is no longer used in version 7.4 and has been removed from the interface.
The Log window now has a new tab named DB List which shows the list of databases currently open by the Board server. To close a database and release memory, use the Unload database function found on the ribbon bar in the Database tab.
The Replicate Entity icon has been moved from the main tab of the Entities window to a new tab, named Advanced, still located in the Entities window.