SQL FastTrack is a powerful and advanced Board Feature, that allows to automatically create and feed a Board database taking data and metadata from one or more SQL sources. The FastTrack reads a relational dataset, automatically analyses it and discovers relationships in the data, generates a multidimensional Board data model and populates it with one click.
It's important to underline the difference between the two instruments, that, at a first sight, may look similar.
SQL DataReader is able to feed an existing DataBase, in other words if you want to use a SQL DataReader you need to define entities, relationships and cubes before loading. On the other hand, FastTrack can work also on new Board databases, creating everything we need automatically.
In few words, FastTrack first creates entities, relationships and cubes then creates and executes DataReaders to feed them.
Let's see how to use the FastTrack.
Before using FasTrack we'll create a new DataBase, then we'll go in
the DatabaseManager tab of board client and click on the SQL FastTrack
icon ![]()
Please note that FastTrack can be used also in existing databases, but we'll describe the simple case.
First we have to name our FastTrack object in the top bar:
![]()
Once you'll save the FastTrack object will always be included in the drop down list.
You can create new FastTracks, rename, save with different name and delete existing ones.
A FastTrack is a collection of Tracks, to create a track add it to the track list with the "Add new Track" command, you can rename a track directly clicking on the name.
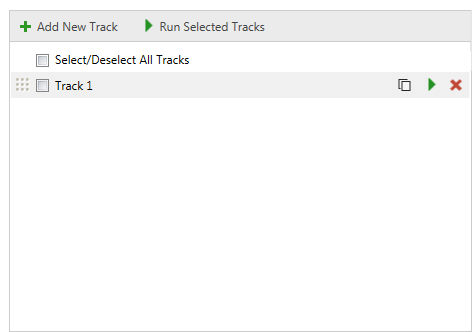
You can select different tracks ticking their checkbox, this will allow you to run multiple tracks each time, clicking on "Run Selected Tracks".
You can run a single track with the "Run this Query" icon
![]() next to your track.
next to your track.
Other actions are "Duplicate Query" ![]() and "Remove this Query"
and "Remove this Query" ![]() .
.
It's time to select our data source. Data sources creation is exactly the same we have in SQL DataReader, so we won't discuss this part.
![]()
Once connected to data source, list of tables and views will appear so that we can define our query with an SQL Statement, (look the sample below)
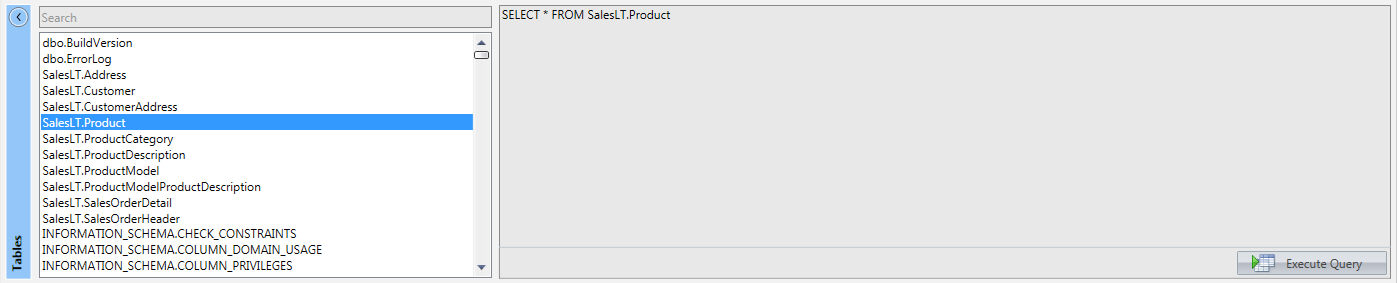
Doble clicking a table will generate the default query:
SELECT * FROM <Table_Name>.
Click on Execute Query in the bottom right of this panel to feed the bottom table.
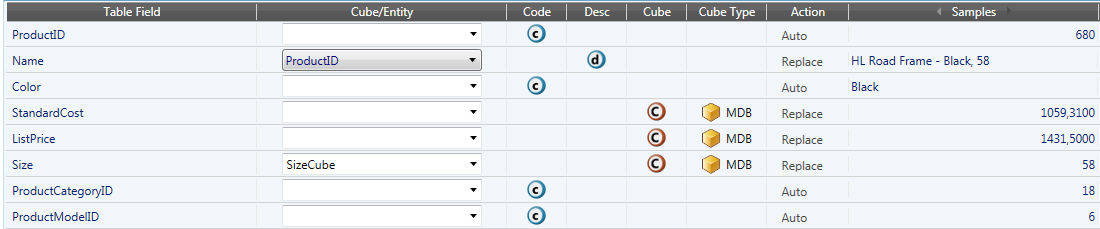
Track definition sample
Table Field: Indicates the column name of the queried SQL table.
Cube/Entity: Name of the cube/entity that will be fed/created. Leaving it blank will result in the default selection. Default selection is the Table Field. This field cannot be left blank for description rows, a description row must be associated to an entity (existing or created in the same track).
Code: Select this if the SQL column contains your entity codes.
Description: Select this if your SQL column contains your entity descriptions.
Cube: If this is a value column, select cube, a cube will be created. Name of the cube is the one in the second field, structure is given by all the entities created/fed with the code or simply read by the Track.
Cube Type: MDB/RDB.
Action: Just like datareader we can set up append and replace modes in this field. In code row we can choose between:
Append - if an item with this code does not exist, it will be created and the record will be considered when loading into the cube;
Blank - Unknown codes will lead to a record rejection;
Auto - Automatic mode, Board will automatically decide basing on the existence of the entity.
In cube row you can choose between Blank (that will sum up values in the same intersections) or Replace that will Replace old values with new values. In Description rows we can also choose between Blank and replace, the first will not change existing descriptions, the latter will replace existing value with the one we are loading.
Samples: This column represents the first queried row, you can scroll to the following ones with the two arrow keys in the header.
The advanced options are in the top right of the FastTrack screen. There are 4 advanced options that can be set up.
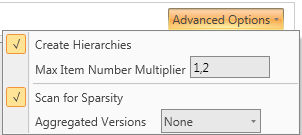
Create Hierarchies: If flagged, it will load implicit relationships along with the entities' definition. In the image above, we are loading four entities: ProductID, Color, ProductCategoryID and ProductModelID, flagging "Create Hierarchies" will result automatically in this kind of tree:
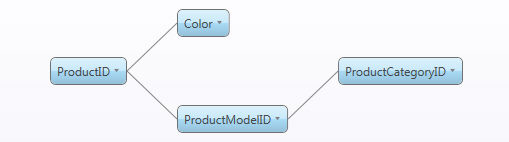 .
.
Without the flag no relationships will be loaded.
Max Item Number Multiplier: it sets up the max item number the following way: for each entity max item number will be: (total items loaded)*(max item number multiplier)
Scan for Sparisty: If flagged, FastTrack will automatically determine Sparsities in the cubes.
Aggregated Versions: We can set up 5 levels of versions, from "None" that will not create additional versions other than the cube default, to "Many" that will create all the possible versions for the cube passing through the three intermediate values "Few", "Normal" and "Huge".
Once you complete the database creation, other than cubes, entities and relationships, you will also see that FastTrack created a set of datareaders. Those datareaders will be the same that FastTrack used to load Entities and Cubes, they're useful if you want to run only a part of a track. (e.g. Product List).
FastTrack is also useful to manage existing databases and integrate them with new data sources or merge different data sources, thanks to its mapping properties.
For example let's consider a database with the entity "Product". We want to add some data taken from a new data source "A" containing its product list. With the FastTrac we can quickly map the new product list on the existing entity product, merging the two list (as a result we'll have the Union of the two lists)