Analytical application requirements continuously change over time, and, consequentially, it is likely you will frequently modify your multidimensional Data Model, adding new Cubes or Entities, changing hierarchy structures, adding new data sources, and so on.
Although some design changes can be implemented directly on the Data Model currently available to end users, it is strongly recommended that you work on a separate copy when implementing fundamental changes, such as adding new Entities, Cubes, or changing hierarchy structures. This separate copy of the main Data Model shouldn't be accessible by any other user during the development stage.
For safety and robustness, two separate environments should be created: one for production and one for development.
The development environment is a Platform that only the Administrator user and any other Developer can access: it closely resembles the production environment and is typically used to develop new Capsules or to make changes to Data Models before deploying them to the production environment, which is the Platform that end users use.
Creating two separate environments prevents both the end users and the Developers from interfering with each other’s work: end users will not interfere with the development of new, multidimensional Objects and, similarly, end users will not be affected by development tasks that could lock a Data Model or absorb a lot of the server’s resources.
For example, a Data Model is always locked while a hierarchy is loaded through a Data Reader and when the process is in progress users cannot access the Data Model.
Only users with a Developer license can access the Data Model section and its features.
General recommendations
A Board Data Model is made of Entities, Relationships, and Cubes, and those elements represent your business. When you create a new Data Model, please bear in mind the following rules and guidelines:
When you create a new Data Model, you must define the Time range of your data: this initial configuration should reflect your existing data lifespan and extend for a few years in the future, for planning purposes.
You can always change an existing time range, but some modifications require additional data management activities, as follows:
The following modifications can happen instantly and don‘t require any reload of data:
Increase the end year (extend future years)
Add or remove Time Entities
The following modifications require clearing all data held by any of the Time Entities to ensure the Data Model is restructured in the most efficient way:
Change the start year (extend or remove historic years)
Decrease the end year (remove data for future years)
To preserve some or all of the data, the Data Model should first be extracted and then reloaded once the modification is made.
The main phases of a Data Model implementation process are the following:
Creation of the Data Model and definition of the time range
Creation of the necessary Entities having their specific max item number
Creation of Hierarchies by defining Relationships between Entities
Creation of the necessary Cubes
Loading data into Entities, Relationships, and Cubes from your data sources
Go live
It's important to follow this very order while creating a new Data Model, because each phase depends directly on the previous one: Entities form the structure of each Cube, while Relationships allow you to define a specific level of detail for data stored in Cubes and to query them at a more aggregate level. The number of Entities in each Data Model should not exceed 1,000 (one thousand). Unrelated Entities set as dimensions in Cubes might generate a huge amount of combinations (cells), thus forcing you to load data for each combination: with Relationships, values are calculated implicitly. The absence of Relationships between Entities can also cause inconsistency and unnecessary redundancy of data in Cubes, resulting in incorrect values in your reports.
Entities
When your Data Model includes a large amount of Entities, it might be difficult locating a specific Entity or understanding the purpose of all Entities listed in the Entities table. In this case, we strongly recommend that you logically group them using the Group field in the Entity metadata panel.
Groups are not part of the multidimensional Data Model (i.e. they cannot be used in reports or Procedures): the only purpose of groups is to improve the organization and, therefore, the ability to search through the list of Entities.
Max item number
When creating a new Entity, it is also important to take into account the potential rate of growth of new members over the life of the application with regards to the "Max item number" value. This value reflects the number of members which can be held within an Entity, and it's what Board uses to optimize the physical data structure of Entities and Cubes. The Max item number can also be left to "Auto"; in that case, Board will automatically define its value based on an internal optimization algorithm.
The maximum Max item number value is [(2^31)-1].
In order to automatically obtain the best possible optimization, you should load your Entities with a significant set of data that truly reflects the capacity of each Entity (not a subset of data) and then load data in Cubes.
When it is not possible to fully load the Entities, for example because only a subset of data is available, or because some Entities will significantly grow over time, then it is recommended to manually define the Max item number for those Entities: it should be set to reflect the estimated number of Entity members.
If a Data reader exceeds the Max Item number when loading Entity members, a warning message appears and the Data reader will discard all excess members from that point on. If the Data Reader log has been enabled from the Data reader table, a log file of the rejected records for each Data reader will be created. Learn more about the Data Reader log.
Modifications
Entity properties can be modified at will as long as the Entity contains no members. When an Entity is populated, you will be able to change the following properties:
Entity name
Code width
Desc width
Sort by
Display
Allow user in view
Is rollup Entity
Unbalanced hierarchy
See creating a new Entity for more details.
Relationships (hierarchies)
In a Board Data Model, Relationships (also called hierarchies) are always hierarchical: a relationship defines a many-to-1 relationship between two Entities that we therefore refer to as the parent Entity and the child Entity. They are often referred to as less-aggregate or more-aggregate Entities.
For example, State and City are clearly parent and child Entities respectively: a city can only be in one state and a state includes several cities.
Building Relationships is one of the key steps in building a Data Model. Hierarchies must provide a truthful representation of the business model or the organization you are modeling. A Relationship between two Entities should only be defined if there is an organizational rule or some kind of requirement that enforces it.
For example, for the State and City Entities, it appears quite obvious that a hierarchical relationship should be defined between the most-aggregate, State (the parent) and the less-aggregate City Entity (the child).
Sometimes the choice is not so obvious. If we consider, for example, the Entities Customer and Salesman defining the hierarchical relationship Customer→Salesman implies that a customer can only be related to a single salesman. If this is always true within an organization, then it makes sense to define a Customer→Salesman relationship. Otherwise, if a salesman manages multiple customers, then those two Entities should remain unrelated.
Cubes
Board Cubes are multidimensional Objects, which are able to store numerical and alphanumerical data (such as images, documents and other files). The data stored in Cubes is held in Cells that are addressed by the unique combinations of the members that make up the Entities which the Cube is dimensioned by.
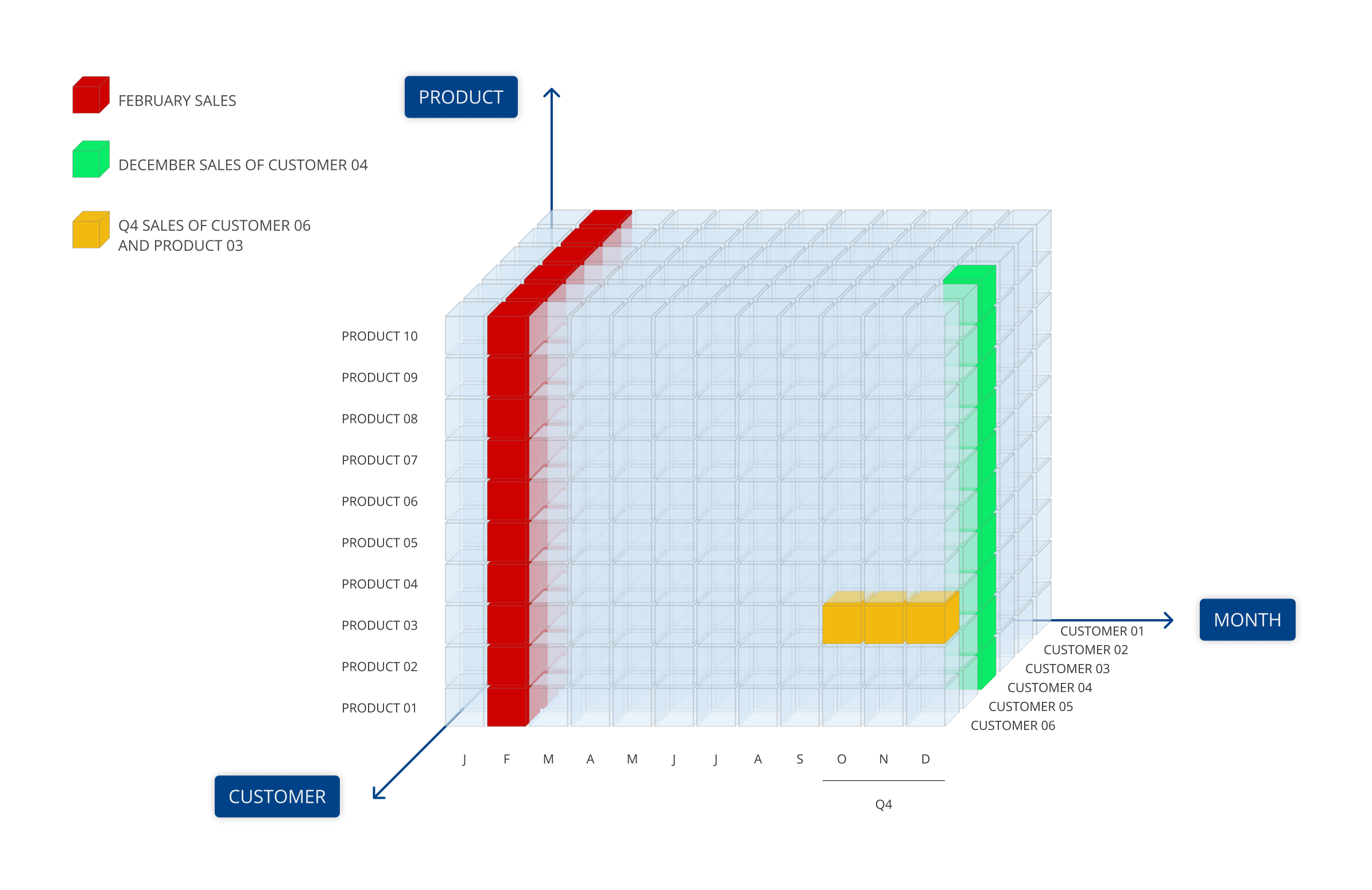
When your Data Model includes a large amount of Cubes, it might be difficult locating a specific Cube or understanding the purpose of all Cubes listed in the Cubes table. Just like with Entities, we strongly recommend that you logically group Cubes using the Group field in the Cube metadata panel.
Groups are not part of the multidimensional Data Model (i.e. they cannot be used in reports or Procedures): the only purpose of groups is to improve reading and searching through the list of Cubes.
When creating a Cube, one of the key considerations is the dimensionality. This is important because it will affect how the data is stored and aggregated as well as allow the act of "drilling" into the data from a more-aggregated view (at a lower level of detail) to a less-aggregated view (at a higher level of detail).
When creating a new Cube, please consider the following points:
A Cube can have a structure from 1 to 32 dimensions. Typically, the number of dimensions of a Cube should not exceed 7 or 8. A Cube with more than 8 dimensions can be difficult for end users to understand and use. Before creating a Cube with more than 8 dimensions, consider revising your Data Model to reduce the number of dimensions.
A Cube can have up to 256 versions. Generally, most Cubes have only one version. You should add other versions only when you really need them: if that is the case, usually 4 or 5 versions are sufficient. Only very rarely are more than 12 versions needed. If you have more than 12 versions of a Cube, analyze if each version is really needed or not.
Each version of a Cube must include at least 1 Entity set as sparse.
For a Cube version that includes a sparse structure, the product of the Max item number of dense Entities has no limits, while the product of the Max item number of sparse Entities must be less than 7.8x10^28 (please note that those numbers are approximations).