Board Engine
Unbalanced hierarchies - Various use cases involving Unbalanced hierarchies have been examined and several improvements have been implemented.
In detail:
Applying a selection to parent and child items using the "Apply selection" Procedure step results in all involved parents to be displayed as selected.
When you extract an Unbalanced hierarchy using the "EXTRACT" feature from the Entities section of the Data Model or the "Extract Entity" Procedure step, the resulting CSV file now has a new "Parent" column specifying the parent member of each child member. In case the "Extract Entity" Procedure step is used, the new column is generated only when the "Tab delimited" option is enabled.
The Layout now correctly handles various cases in which Unbalanced hierarchies are set By Row or By Column and they are nested (i.e. they are set together with other Entities and they are in the rightmost position in the axes fields). Now row totals and down totals are calculated considering only ancestors (i.e. root members of the hierarchy that don't have parents). The new behavior only works if the "Summary" property for the Block is set to "Total".
Since the value of Parent members is calculated on the fly in the Layout, the "Refer To" option set on a Parent member was not supported.
Now the "Refer To" option is also supported by Unbalanced Hierarchies and works as follows:If the Unbalanced hierarchy is not in the axes of the Layout, the result displayed is the sum of all descendants in the active branch of the tree
If the Unbalanced hierarchy is set By Row or By Column, the value of the selected member is correctly replicated to all items in the active branch of the tree down to the deepest member. All the usual on the fly calculations along the tree, in this case, are not executed and the "Refer To" option works just as it does for "regular" Entities.
Diagnostic log - The Diagnostic log launched in the 2021 Winter release has been enhanced to include more system-level information, more configuration-related events, and a much richer level of detail regarding Data Model elements.
The following improvements have been implemented:
The default verbosity level has been changed from "Warning" to "Information".
The log filename now has the following format: diagnosticYYYYMM_tsv.log.
After the "diagnostic" prefix, the two timestamps indicate the year (yyyy) and the month(MM), respectively.Rolled log files now have the following format: diagnosticYYYYMM_tsv.archive###.log.
After the "diagnostic" prefix, the two timestamps indicate the year (yyyy) and the month(MM), respectively. After "archive", an incremental value is added as files are rolled (001, 002, etc.).The format of the logged information has been changed from JSON to TSV (tab-separated values) with column headers in the first row.
Logging verbosity levels for each event have been reviewed so that each level provides an appropriate set of information.
All requests that can be received by the engine have been reviewed and, where possible, additional information has been added.
The event start and event end log entries now include more information about the logged event. In particular, the event end log entry includes a specific "Elapsed (ms)" column whose value indicates the processing time after which the engine sent the response.
If a request received by the engine is not from the Board web client - as it is the case with Board's Office Add-ins -, the corresponding entry now includes a specific property (application_ID) next to the triggered engine event.
Example2022-12-07 11:02:54.129 +01:00 INFO Administrator 5761e6aa-e6ae-4078-bbd2-53c36067d81a NET_Connect [OFFICE_ADDIN] Starting action.Log entries regarding the Layout now include additional information, as described below:
The Layout start event entry now includes client filters (Active selection, Pagers definitions), the Layout definition (Blocks and Entities in the axes), and Block and Axes Properties. Block and Axes Properties are logged only if their settings are different from the default settings.
Example2022-12-02 12:12:20.361 +01:00 INFO Administrator 3a43b5b9-a022-4a8a-b29a-268ccce078d9 NET_LayoutToSpread DataEntry Log.bcps Home {"ClientFilters":{"Selections":[{"Entity":"E_000201 D011 Customer", "Members":["1 C1","2 C2","3 C3"], "Mode":"Keep"},{"Entity":"E_000007 A007 Day", "Members":["1 20200101","2 20200102","3 20200103","4 20200104","5 20200105","6 20200106","7 20200107","8 20200108","9 20200109","10 20200110","11 20200111","12 20200112","13 20200113","14 20200114","15 20200115","16 20200116"], "Mode":"Keep"},{"Entity":"E_000206 D016 Custom Sort", "Members":["3 c","4 d"], "Mode":"Exclude"}], "Pages":[{"Entity":"E_000202 D012 Product", "Members":["3 P3"], "Mode":"Keep"}]}, "CoreLayout":{"ByRow":["E_000001 A001 Month","E_000204 D014 Country","E_000201 D011 Customer"], "ByCol":["E_000202 D012 Product"], "Blocks":[{"Letter":"a", "Cube":"V0001 Gross Sales", "DataEntry":{"SplitSplat":false}},{"Letter":"b", "Cube":"V0009 Gross Sales V4", "ReferTo":[{"Entity":"E_000006 A006 Year", "Members":["2020"], "Mode":"Keep"}], "TotalByEntities":"E_000203 D013 City, E_000006 A006 Year"},{"Letter":"c", "Cube":"V0001 Gross Sales", "TimeFunction":{"BlockFunction":"Value", "PreviousYear":true, "PeriodOffset":100, "PeriodCycle":200}},{"Letter":"d", "Cube":"V0009 Gross Sales V4", "Rule":{"Title":"N.A. 1"}, "RollupCube":true},{"Letter":"e", "Algo":"a + 100", "Summary":"Calculated"},{"Letter":"f", "RowTotals":false, "Rule":{"Title":"N.A. 1"}},{"Letter":"g", "Entity":"E_000006 A006 Year", "RowTotals":false, "TooltipBy":"a", "DetailBy":{"Entity":"E_000001 A001 Month", "KeepTop":12, "Sort":"Descending"}},{"Letter":"h", "RankingFunction":"Counter", "Summary":"Calculated", "RowTotals":false, "Aggregation":{"Mode":"AVG", "Entity":"E_000008 A008 Week"}},{"Letter":"i", "Cube":"V0001 Gross Sales", "AnalyticalFunction":{"Function":"Nascency", "TimeEntity":"E_000001 A001 Month", "From":0, "To":0, "IgnoreLastPeriod":false}},{"Letter":"j", "Cube":"V0001 Gross Sales", "DataEntry":{"SplitSplat":false, "PatternBasedAllocation":{"Cube":"V0009 Gross Sales V4", "PreviousYear":true}, "LockedByBlock":{"LockerBlock":"c", "LockIsZeroMode":true}, "LockByCube":{"LockerCube":"V0002 Rolap Single", "DisplayBothLockAndFree":true, "LockNotZeroMode":true}}},{"Letter":"k", "Cube":"V0001 Gross Sales", "AlertBy":"a", "DataEntry":{"SplitSplat":false}, "Nexel":{"Mode":"SingleRule", "Formula":"=100", "TotalFormula":"=10000"}}], "DifferentiateZeroNull":true}} Layout started.The Layout end event entry now includes the number of rows, columns, and cells generated as a response to the Layout query.
Example2022-12-02 12:12:21.954 +01:00 INFO Administrator 3a43b5b9-a022-4a8a-b29a-268ccce078d9 NET_LayoutToSpread DataEntry Log.bcps Home {"Rows":9, "Columns":20, "Quota":180} Layout completed.
Log entries regarding data entry events now include additional information, such as client filters (Active selection, Pagers definitions), the Layout definition (Blocks and Entities in the axes), and Block and Axes Properties. These entries also include the following details specific to data entry actions:
Position of the cell where the data entry action occurred (row number, column number, cell coordinates).
Entered value.
Previous value.
The header of the Block affected by the data entry action, as shown in the Layout editor (i.e. "a", "b", "c", etc.).
Example2022-11-30 11:20:15.892 +01:00 INFO Administrator 6aab0bfb-4bb9-4cef-95d7-6f19cb9a28e4 NET_DataEntry DataEntry Log.bcps Dataentry {"ClientFilters":{"Selections":[], "Pages":[]}, "CoreLayout":{"ByRow":["E_000001 A001 Month","E_000202 D012 Product","E_000201 D011 Customer"], "Blocks":[{"Letter":"a", "Cube":"V0001 Gross Sales", "DataEntry":{"SplitSplat":true}, "Nexel":{"Mode":"SingleRule"}}], "RowShowAll":true}, "CellChanged":[{"Row":11, "Col":2, "OldValue":300, "NewValue":3000, "Coordinates":"1 202001, 2 P2, 2 C2", "Block":"a"}]}
Log entries regarding Data readers now include additional information, as described below:
The Data reader start event entry now includes the protocol name and the path to the file that should be read (only for text file Data readers).
Example2022-12-02 11:38:32.933 +01:00 INFO 537bd1ed-e8be-40a6-b6aa-92e185571ad0 d8a4898d-1ac4-440c-ae03-b9940afb5996 DataRead sync {"ClientFilters":{"Selections":[], "Pages":[]}, "DataReader":{"Title":"SyncToDataModelTemporary", "Path":"C:\\Windows\\TEMP\\tmp2117.tmp"}} Data reader started.The Data reader end event entry now includes the number of successfully processed rows, discarded rows, and the error message (if any).
Example2022-10-25 12:40:18.241 +02:00 INFO Administrator 537bd1ed-e8be-40a6-b6aa-92e185571ad0 DataRead ce788c9f-bf3d-48ef-938f-12253ae40704 ASCII Data Read Echo {"Stats":{"ReadRecords":2, "DiscardedRecords":5, "ErrorMessage":"Error : RBT1825 New Item Found on column 1 [Joan \"the bone\", Anne]"}} Data reader ended.
Log entries regarding Dataflows now include additional information, as described below:
The Dataflow start event entry now includes the client filters (Active selection, Pagers definitions) sent with the Procedure step.
Example2022-11-25 17:47:03.887 +01:00 INFO Administrator e03b5b6a-d11e-4cb2-b2f9-26d1862a8a82 dataflow 68dea0cd-a9cc-4fa7-8fc7-d3b0037f4530 3. Data flow Echo {"ClientFilters":{"Selections":[{"Entity":"E_000001 A001 Month", "Members":["1 201001"], "Mode":"Keep"}], "Pages":[]}} Dataflow started.The Dataflow end event entry now includes various additional information about its configuration, such as the target Cube, the algorithm used for the calculation, the details of the "extend" option configured by the user, the details of the "extend" option applied by the system, and others.
Example2022-11-25 17:47:06.140 +01:00 INFO Administrator e03b5b6a-d11e-4cb2-b2f9-26d1862a8a82 dataflow 68dea0cd-a9cc-4fa7-8fc7-d3b0037f4530 3. Data flow Echo {"DataFlow":{"Target":"V156 Sales pacl", "ContainingPlus":true, "Algo":"Tuples.[Union].InnerOuter", "UserExtend":"E_000001 A001 Month, E_000011 D011 Customer", "InternalExtend":"E_000017 D017 Product", "RollOver":"V226 Gross Sales", "BackCompatible":false}} Dataflow ended.If a Cube configured in the "Limit calculation to tuples of the Cube" option is not found when the step is executed, the Procedure will fail and a specific error message will be displayed. This may happen, for example, when the Cube is configured in the "Limit calculation to tuples of the Cube" option and that same Cube is later deleted from the Data Model.
Example2023-03-22 10:47:03.058 +01:00 WARN Administrator f04dfa9d-4e0f-427e-856b-eeb527813ea2 Rollover 7d6e289a-f71a-4094-aa00-81f3952d3e6b 3. Data flow Echo Unable to find rollover cube. Rollover cube will be ignored. Dataflow revert to default calculation domain option.
Log entries regarding Procedure steps (start event, end event, additional action events), now include the step number as it is displayed in the Procedure designer.
Example2022-12-02 10:38:28.011 +01:00 INFO Administrator 1e4b6e48-0672-4cb4-a7f2-69901d767b42 select based on 27b14850-6886-4110-bf79-8f8a09fb70ea 5. Data flow DP {"ClientFilters":{"Selections":[{"Entity":"E_000036 D036 Currency", "Members":[], "Mode":"Invalid"},{"Entity":"E_000027 D027 Merch_Zone", "Members":["10 10","11 11"], "Mode":"Keep"}], "Pages":[]}} Dataflow started. (bold added)If one or more dimensions of a Cube are missing in the Data reader mapping configuration, a new specific log entry is created for each missing dimension in the Diagnostic Log set to verbosity level "Warning". The Log entry would look like the following example:
2023-03-16 12:44:12.931 +01:00 WARN Administrator d6f45ad2-4359-4963-9467-6892b8b8bf9f Import in Gross Sales a8db4810-f525-4993-b369-3a4ea12e2d5a 2. ASCII Data Read Echo {"Cube":"V001 Gross Sales", "MissingEntityIdx":3} Cube dimension is missing in mappings.
If a log entry mentions a Data Model resource (Entities, Entity members, Cubes, and Sparsities), the reference to the corresponding resource is now presented as described below:
Entities → "{Physical name} {Internal identifier} {Extended Name}". Example:
"E_000036 D036 Currency"Entity members → "{Internal identifier} {Code}". Example:
"10 202212"Cubes → "{Physical name} {Name}". Example:
"V156 Sales EMEA"Sparsities → "{Sparsity code} {Internal identifier}", Example:
"SP001 D0014#"
If one of the resources mentioned above cannot be found, the related information in the corresponding entry is logged as follows: "N.A. {Internal identifier}". Example: "N.A. 13"
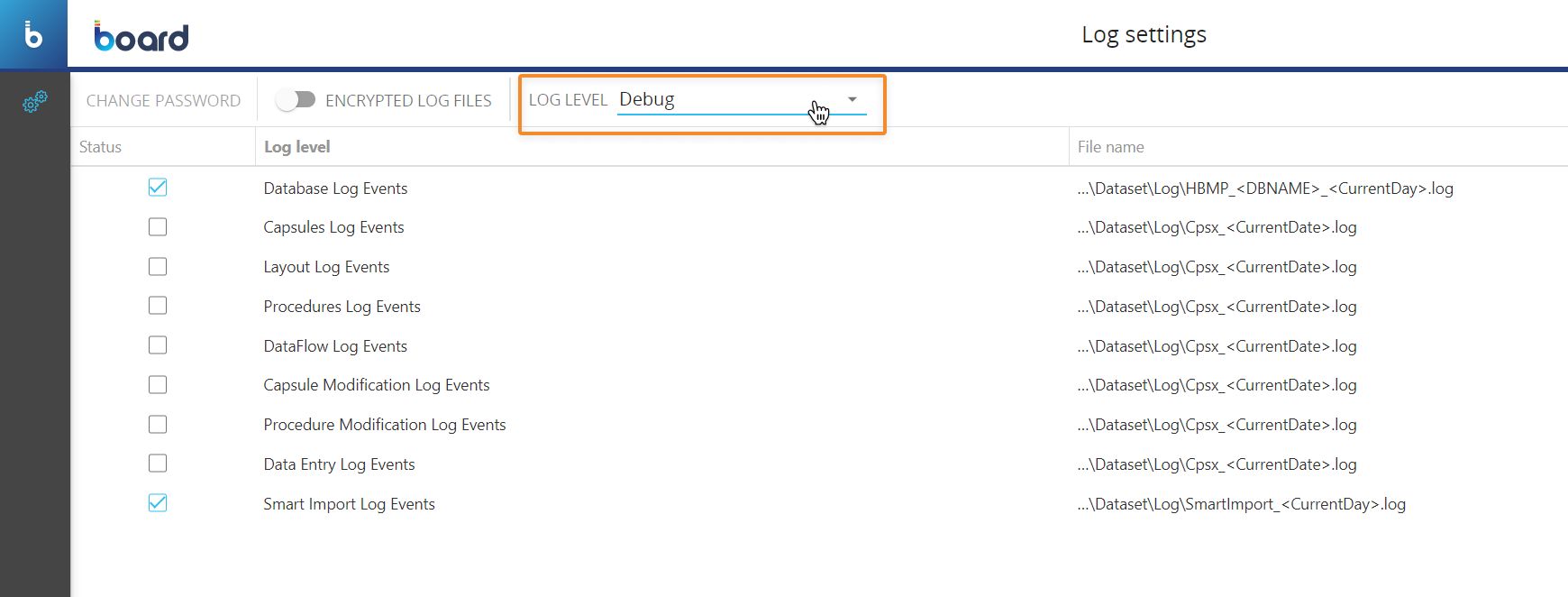
Diagnostic log verbosity level - The verbosity level of the Diagnostics log now can be changed on the fly. You can check and change the current verbosity level through a new dropdown menu in the "Log Settings" section under "System Administration". Thanks to this improvement, it is no longer necessary to restart the Board engine service to change the verbosity level of the Diagnostic log.
Temporary Cubes in Data readers - Temporary Cubes are now supported in Data readers, giving Developers a lot more flexibility in terms of Procedure design and reducing the need for Cube maintenance and possible concurrency issues, for example when multiple users update the same Cube via multiple instances of the same Procedure.
The configuration of a Data reader with Temporary Cubes is the same as a regular Cube, except for the mapping phase.
To map a Temporary Cube to your data sources, proceed as follows:
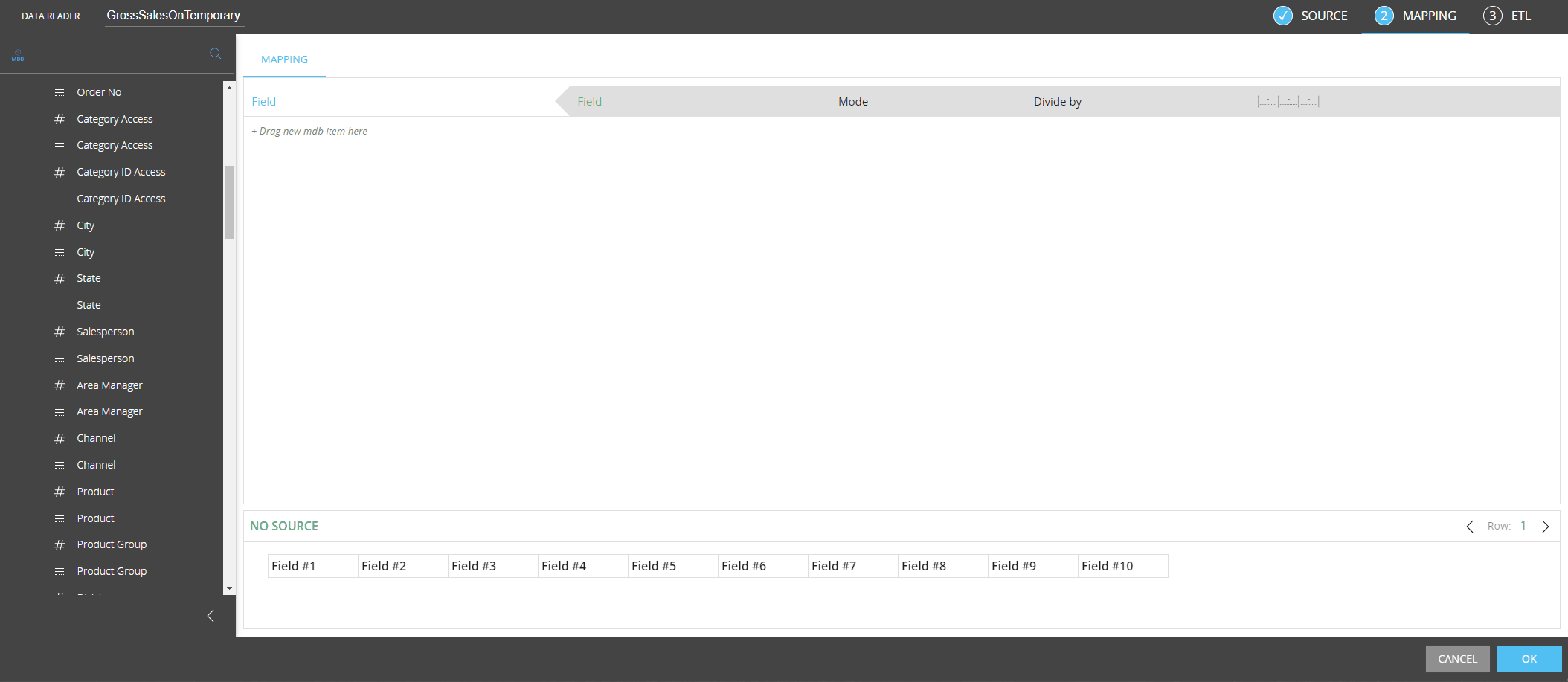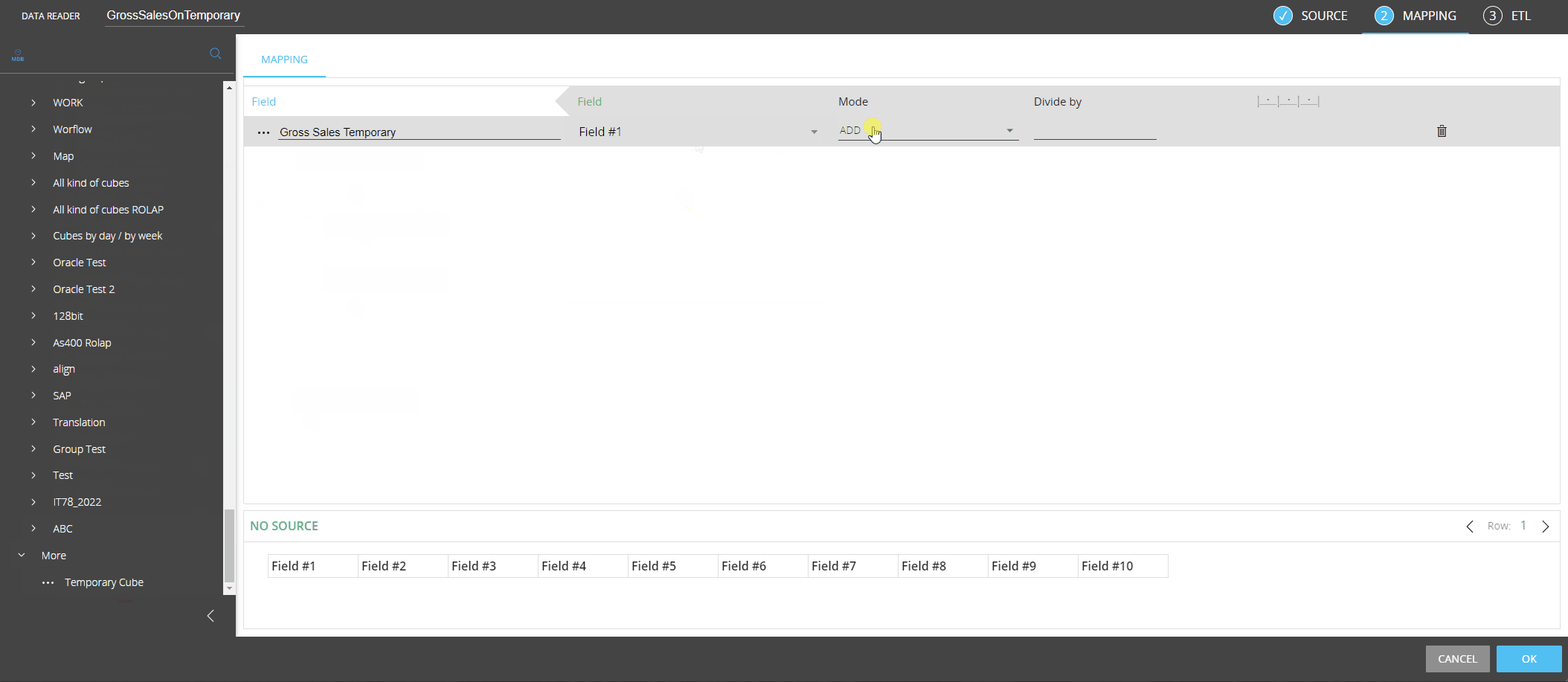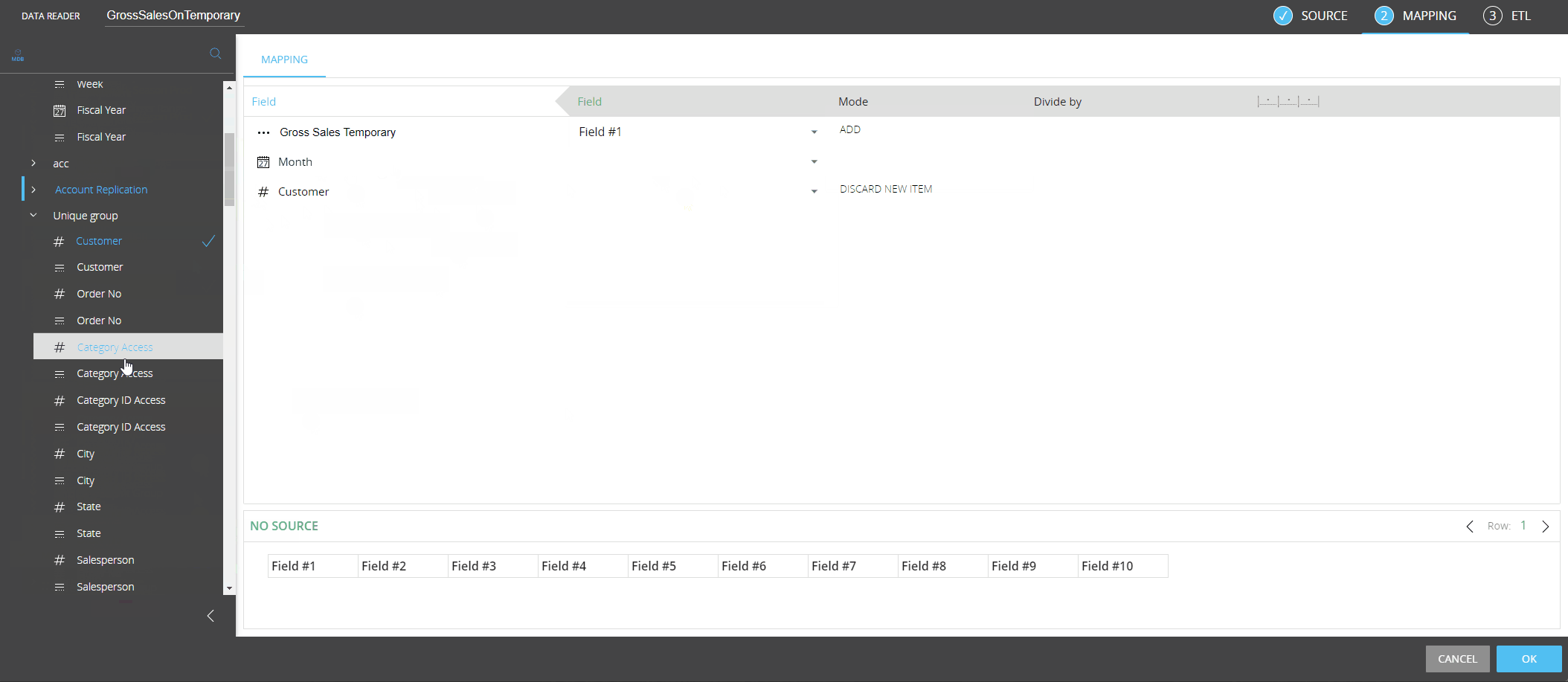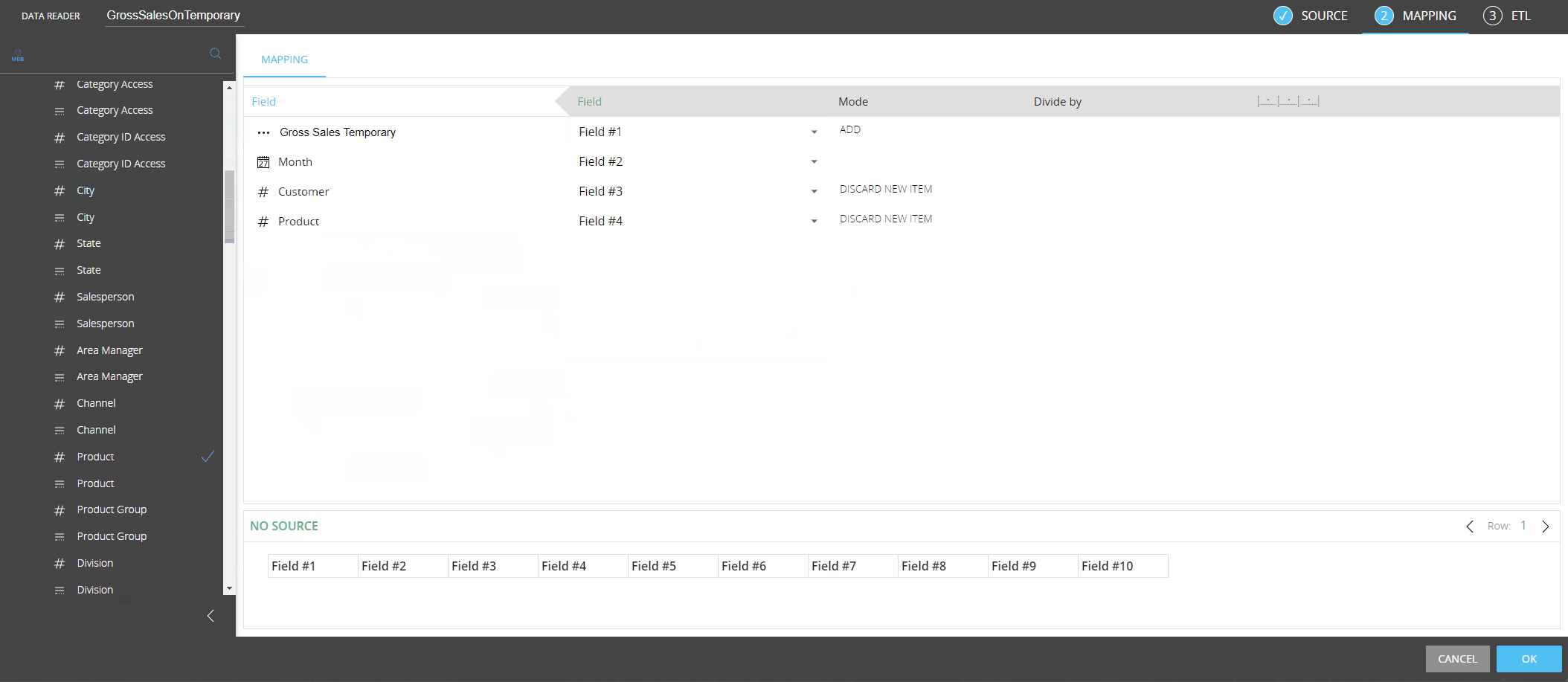
From the left-hand side of the Mapping page, drag the new "Temporary Cube" object from the "More" group to the center area outlined in blue.
Enter the Temporary Cube name in the "Temporary Cube name" placeholder. The name must match exactly the name you chose during the creation of Temporary Cube.
Drag the code placeholder (and the description placeholder, if needed) for each dimension of the Temporary Cube structure from the "Entities" group to the center area outlined in blue. For regular Cubes, those Entities are automatically added when you drag the Cube in the mapping area, but this is not the case for Temporary Cubes: you must add the code placeholder (and the description placeholder, if needed) by hand for each dimension, which must match the dimensions in the structure of the Temporary Cube.
If the Temporary Cube name and/or the dimensions entered in the Data reader mapping page do not match the actual name and the dimensions of the Temporary Cube, no data will be imported, but the Data reader won't fail.
If a manually entered Temporary Cube name does not match the actual Temporary Cube name in the Procedure, in the Diagnostic Log set to verbosity level "Warning" a new specific log entry will be created. The Log entry would look like the following example:
2023-03-16 12:35:59.053 +01:00 WARN Administrator 491b04bb-6b4e-4c3a-9b36-88e2cc1d9405 DataRead 15affa90-7e50-4a7b-93f8-7343753a78ad 2. ASCII Data Read Echo No virtual cube defined. A required virtual cube definition was not found by name: Gross Sales Temporary. DR mapping removed.
If one or more dimensions of a Temporary Cube are missing in the mapping configuration, a new specific log entry will be created for each missing dimension in the Diagnostic Log set to verbosity level "Warning". The Log entry would look like the following example:
2023-03-16 12:44:12.931 +01:00 WARN Administrator d6f45ad2-4359-4963-9467-6892b8b8bf9f Import in Gross Sales Temporary a8db4810-f525-4993-b369-3a4ea12e2d5a 2. ASCII Data Read Echo {"Cube":"T001", "MissingEntityIdx":3} Cube dimension is missing in mappings.
Since Temporary Cubes are created and used only as part of the Procedure in which they are defined, manually running a Data reader that imports data in Temporary Cubes from the Data reader home page will not produce any results (on Temporary Cubes). These new Data readers should be used only in the Procedure in which the Temporary Cubes were created.
Example
In a Procedure, the following Temporary Cube definition has been defined:
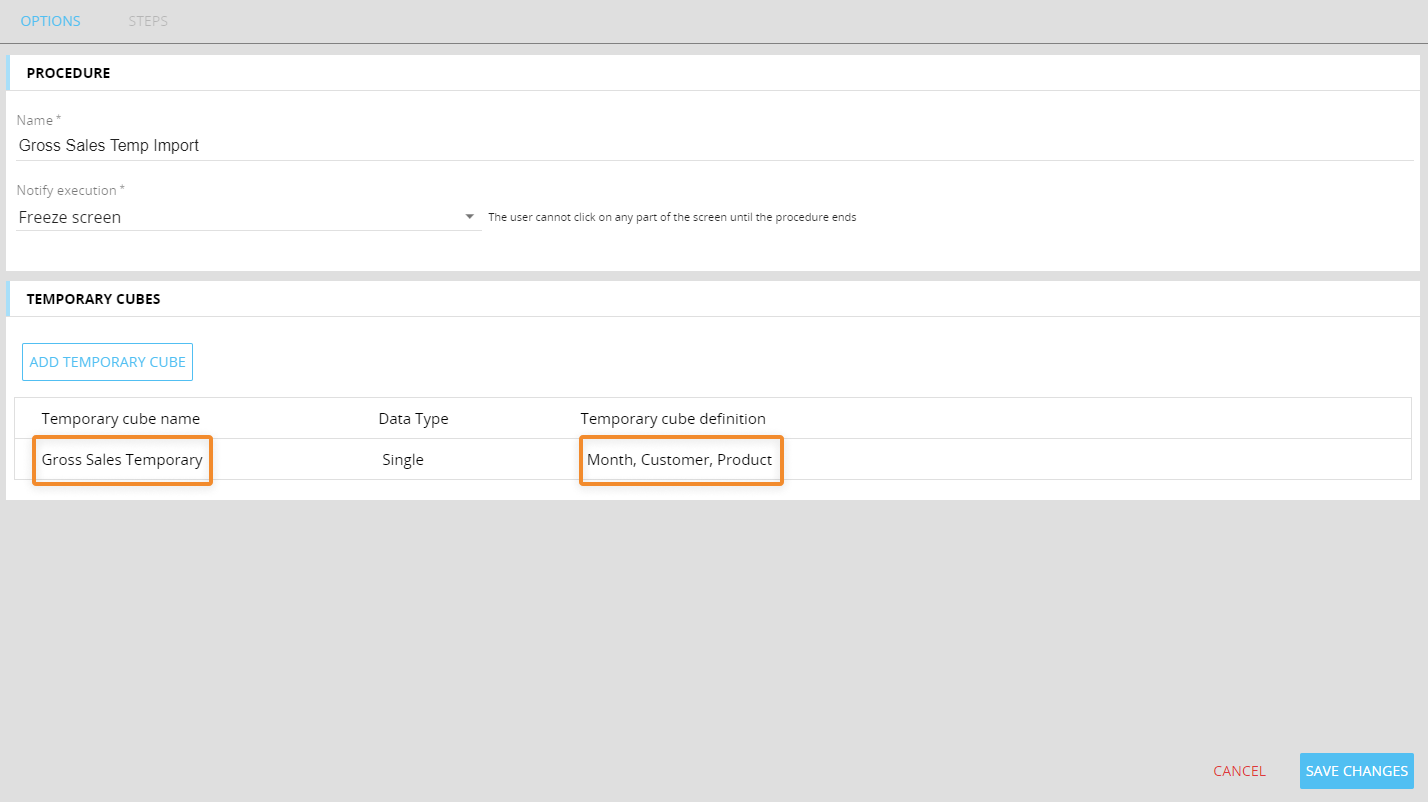
If you wanted to use that Cube in a Data reader, the configuration would be as follows:
Temporary Cubes in Procedure steps - The use of Temporary Cubes has been extended to all Procedure steps whose configuration includes a Layout or other Cube-based options.
Please note that:
In the Dataflow step, if a Temporary Cube used in the Layout is not found when the step is executed, the Dataflow will fail. This may happen, for example, when a Cube is configured in a Dataflow Layout and that same Cube is later deleted from the Procedure.
In the Dataflow step, if a Temporary Cube configured in the "Limit calculation to tuples of the Cube" option is not found when the step is executed, the Procedure will fail and a specific error message will be displayed. This may happen, for example, when the Temporary Cube is configured in the "Limit calculation to tuples of the Cube" option and that same Cube is later deleted from the Procedure.
In all steps affected by this implementation, if a Temporary Cube used in the Layout or in a Cube-based setting is not found when the step is executed, the Procedure will fail and a specific error message will be displayed. This may happen, for example, when a Cube is configured in a setting and that same Cube is later deleted from the Procedure.
In the "Export Data View to file" step, the Yearly Cumulated Value function is not supported when applied to a Temporary Cube in the Layout
When a Temporary Cube holds data, it is treated as a regular Cube in terms of logging, selections based on Cube (and not Dynamic), and all other features available for regular Cubes.
A Procedure where Temporary Cubes are configured as per the new implementation cannot be executed in previous versions of Board
Temporary Cubes are not considered in the Impact Analysis section.
As a consequence of this new implementation, we have removed the Dataflow Analysis feature from the Dataflow configuration (the cog icon in the "CALCULATION DOMAIN" menu) and the "SCAN DATAFLOW ACTIONS" button in the OPTIONS tab in the Procedure configuration panel.
Data reader - Board standard Time Entities now natively accept the following date formats for time periods loaded through a Data reader.
Entity | Width | Format | Example |
Day | 6 | YYMMDD | 221222 |
Day | 8 | DDMMYYYY | 31122022 |
Day | 8 | YYYYMMDD | 20221231 (recommended) |
Week | 4 | YYWW | 2248 |
Week | 5 | YY?WW | 22-48 |
Week | 6 | YYYYWW | 202248 (recommended) |
Month | 4 | MMYY | 1222 |
Month | 4 | YYMM | 2212 |
Month | 5 | MM?YY | 12-22 |
Month | 5 | YY?MM | 22-12 |
Month | 6 | MMYYYY | 122022 |
Month | 6 | YYYYMM | 202212 (recommended) |
Quarter | 4 | QQYY | 0322 |
Quarter | 4 | YYQQ | 2203 |
Quarter | 5 | QYYYY | 32022 |
Quarter | 5 | YYYYQ | 20223 |
Quarter | 6 | QQYYYY | 032022 |
Quarter | 6 | YYYYQQ | 202203 (recommended) |
Year | 2 | YY | 22 |
Year | 4 | YYYY | 2022 (recommended) |
Performance improvements - In previous versions of Board, updating a Database security profile or a row style template required the Data Model to be unloaded and reloaded in memory to apply changes: this could freeze the system and cause other service reliability issues. Now administrators can update Database security profiles and row style templates without causing stability or performance problems.
Various
Smart Import Object enhancements - The following column sources have been added to the Smart Import object:
Fixed values. This option allows you to write a custom fixed value to a target Cube or Entity code/description for each row of data submitted.
Formulas. This option allows you to map the result of a formula to a target Cube or Entity code/description for each row of data submitted.
Read more on the Smart Import Object documentation page.
Customizable Session Expiration Timeout - In previous versions, the session expiration timeout was set to a default value (1 hour) that could not be modified. Now the session expiration is disabled by default and, when the session expiration is enabled, the timeout can be modified.
The following rules apply to this new feature:
The timeout value represents the number of seconds before the session expiration.
The default timeout value is 3600 seconds (which equals 1 hour).
The highest timeout value allowed is 3600 seconds. If you set it to a higher value, it will be automatically reduced to 3600.
When a session expires, the log-out process may take a few moments to complete.
If you need to customize the Session Expiration Timeout for your Board Platforms, please submit a ticket through the Board Support site: the ticket must contain your Platform name (e.g. customer1-s1.board.com). The Board Cloud Operations team will then handle your request.
Sparsity management & optimization - Due to misconfigurations of calculation steps in Procedures (for example in Dataflows with the “Extend calculation” option set on the sparse dimensions of the target Cube), the sparsity of Cubes could increase enormously and that made interaction with said Cubes in the administrative area of Data Models very difficult.
In previous versions, administrators could only spot this malfunction by looking into sparsity files in the mapping folders of each Data Model and in Board there was no indication about the sparse combinations in use by the Cube.
To solve this problem, administrators had to eliminate the unnecessary combinations in all Cubes by clearing and reloading all Cubes in bulk, even those that had nothing to do with the sparsity problem.
The new update of the Sparsity details page under the Analysis tab in the Cube details panel, allows administrators to:
• Easily spot sparsities that contain huge amounts of combinations.
• Easily identify which Cubes use huge sparsities.
• Easily delete the unused sparse combinations in huge sparsities to optimize hard disk space usage and speed up the interaction with the affected Cubes.
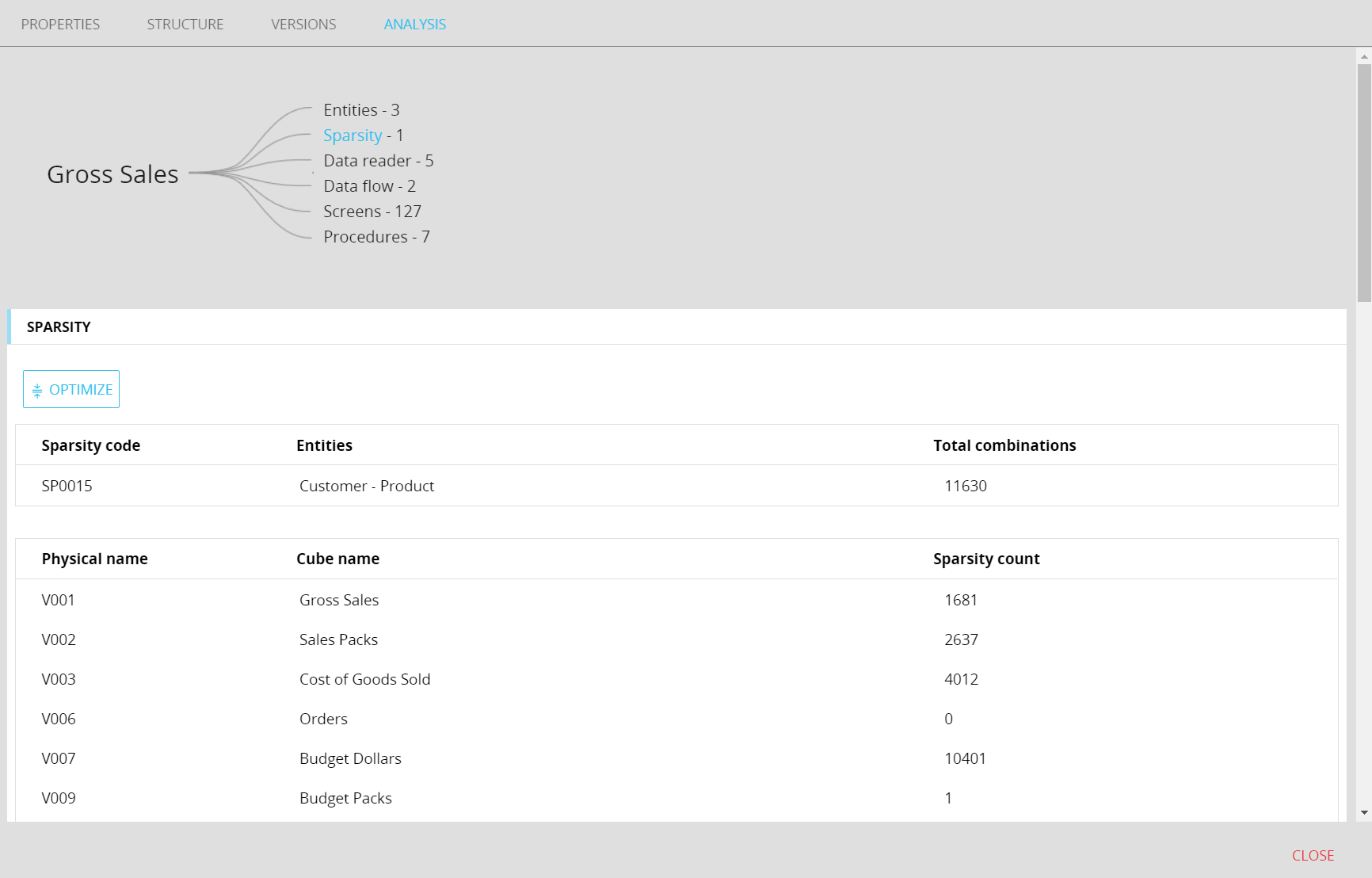
When the user clicks on the “Sparsity” element of the graph, the details about the sparsity in use now include the following info and features:
• The number of combinations of the sparsity used by each Cube.
• A dedicate button next to the total combination of the sparsity which launches the optimize function.
The new page allows to easily spot those Cubes that are responsible for the abnormal sparsity growth, so that an administrator can clear and reload them before launching the reduction function.
The optimize function can be launched from any Cube analysis page, provided the selected Cube is using the sparsity that needs to be optimized: when the function is launched, it searches for unused combinations of the sparsity in all Cubes which are using it and deletes them.
During the optimize function execution, the Data Model is put into maintenance mode. Depending on the sparsity usage, the execution may take a few minutes or more.
Broadcasting emails - The Broadcasting emails now can also be sent from the European Union (EU), whereas previously they could only be sent from the United States.
If you would like to configure a preferred zone for sending Broadcasting emails, for example for GDPR compliance, you can raise a ticket through the Board Support site.
Board PowerPoint add-in - Previously, the Board PowerPoint add-in had some performance issues when handling Presentations with more than 5 Slides. This has been fixed along with other performance optimization issues so that the Add-in now runs faster and consumes fewer resources.
Board Excel add-in - The Board Excel add-in now includes a new option that manages all cases where two or more Layouts overlap on the same origin cell. This happens, for example, when the user applies the format of a table over another table using the Format Painter tool, or when the user copies and pastes an entire cell range to another cell range which already has values coming from another Layout definition.
In these cases, Layouts are "stacked" one on top of the other and, over time, this can lead to potential performance issues, unexpected results and extensive waiting times, as the Layout execution becomes very taxing on the connected Board Platform.
The new "Remove overlapping layouts" option allows the user to decide which Layout should be retained when the worksheet or workbook gets refreshed via the "Refresh Sheet" or the "Refresh Workbook" buttons respectively.
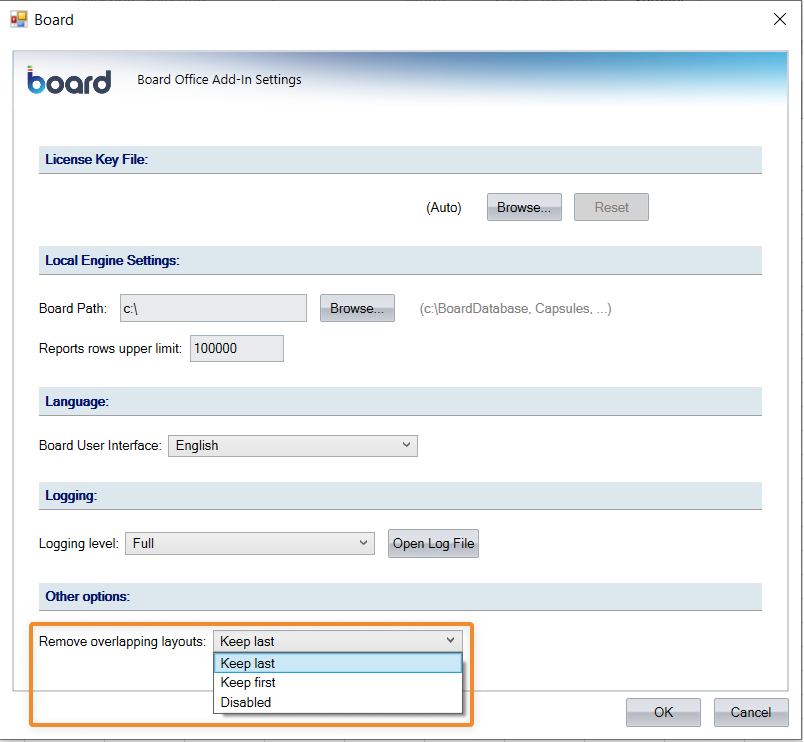
The option offers the following settings:
Keep last. This option removes all Layouts and keeps only the most recent one, based on its creation date. The removed Layouts are deleted upon refreshing and cannot be recovered.
Keep first. This option removes all Layouts and keeps only the least recent one of all, based on its creation date. The removed Layouts are deleted upon refreshing and cannot be recovered.
Disabled (default). In this case, all Layouts in the worksheet or workbook are kept and refreshed, even the overlapping ones.
Please note that this setting applies only when two or more Layouts overlap in the Excel sheet or workbook.