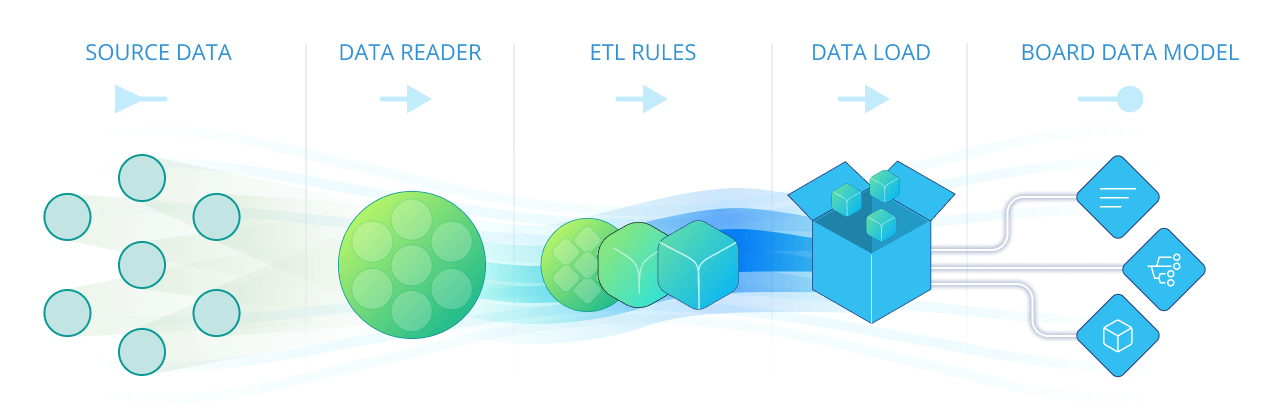
Board's Data Reader protocol (also called simply Data Reader) allows you to import data into a Board Data Model from text files or from ODBC, OLE DB, and other external data sources using Board's robust set of connectors. A Data Reader protocol defines how the external data is to be imported into the corresponding Board Data Model and how it is mapped to Entities and Cubes: in other words, it determines which fields of a file or a table in a relational database should be fed into which Entities and Cubes.
A Data Reader protocol can feed multiple Entities and Cubes at the same time and, similarly, Cubes, and Entities can be loaded from multiple Data Reader protocols.
For example, if you need to feed 2 Cubes, Sales Amount and Sales Quantity, with data that resides in the same table of your transactional system, then you can create a unique Data Reader protocol that loads both Cubes at the same time.
On the other hand, if you need to feed a Cube from 2 transactional systems, you can create 2 protocols which load data into the same Cube but connect to a different data source. This is useful, for example, when you need to consolidate data from multiple subsidiaries that have separate ERP systems.
A Data Reader protocol can include transformation formulas and validation rules which are automatically applied to the incoming data. These rules and formulas are defined using the ETL section of the Data Reader configuration area.
Data Reader protocols can be launched from a Procedure or directly from the Data Reader section of the Data Model. Usually, Board Data Models are updated daily with a scheduled overnight process that runs all required reading protocols.
It is important to note that a Data Reader reads data records in parallel of each other to execute faster.
The mapping and ETL sections of the Data Reader are two of Board's data ingestion core capabilities, which translate into tangible savings while implementing a project. With the power and flexibility of the Data Reader, in most cases you will be able to feed your Board Data Models directly from the source system (such as an ERP, CRM, or other operational tools) without the need for intermediate data staging layers, such as a data-mart or a data-warehouse. This is unique in comparison to most other planning platforms, which typically require the source data to be cleansed and organized in either a star or snowflake schema: this process can be a significant cost during implementation, but it is often overlooked.
To access the Data Reader section of a Data Model, access the designer space of the desired Data Model and click on the Data Reader tile.
In the Data Reader page, you can see all existing Data Reader protocols in the Data Model and their main information: the table is sortable and searchable using the interactive header fields. You can also show or hide columns to your liking, by clicking the Column chooser button in the upper right corner of the table.
You can perform different actions on one or more Data Readers by selecting them and by clicking on the different buttons above the list. See Running and managing Data Reader protocols for more details.
When your Data Model includes a large amount of Data Readers it might be difficult locating a specific one or understanding the purpose of all Data Readers listed in the table. In this case, we strongly recommend that you logically group them using the Group cell in each row.
Groups are not part of the multidimensional Data Model (i.e. they cannot be used in Procedures): the only purpose of groups is to improve viewing and searching through the list of Data Readers.
The Data Reader section of each Data Model in Board allows you to:
Create, delete, copy, and run Data Readers.
Edit any of the 3 main configuration steps of each Data Reader (Source, Mapping, and ETL).
Enable event logging for specific Data Readers. This option creates a log file with all discarded records. If no record is discarded, then no log file is created. However, the general Data Model log file always contains a log line related to each Data Reader execution.
The log file with the rejected records is created in the following locations:For Text file Data Readers, in the same path where the source text file is located.
For SQL Data Readers, in the "Other logs" folder under the "Logs" section in the Cloud Administration Portal. The log file name includes the Data Reader name, the Data Reader ID, and the timestamp. For example, SourceData_025_202208.log.
For SAP Data Readers, in the "Other logs" folder under the "Logs" section in the Cloud Administration Portal. The log file name includes the Data Model name, the Data Reader ID, and the timestamp. For example, Production_9958_202208.log.